머신러닝과 딥러닝 기초
인공지능의 정의를 개인이 내리는 것이 중요함 -> 사람처럼 하는 프로그램
프로그래밍과 머신러닝의 차이
머신러닝 : 데이터를 사용해서 해결패턴을 스스로 찾아냄
딥러닝 : 머신러닝의 한 방법중 하나, 그동안 머신러닝으로 해결되지 않았던것 ex) 컴퓨터 비전 을 해결하는 해법중 하나
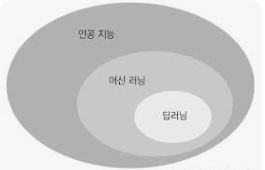
머신러닝의 세가지 학습방법
지도학습 : 오늘 배울 내용 거의 90% 이상이 지도학습( 문제집, 정답) (독립변수, 종속변수)(특성feature, 레이블targer)(x, y)
1) 이진분류 : 정답이 둘중 하나인경우 ex) 삶
2) 다중분류 : 정답이 여러개 중에 하나인 경우 ex) 차종, 학년
3) 회귀 : 연속적인 값을 예측하는 것(수치) ex) 관객수, 투자
비지도 학습 : 정답이 있는 데이터가 아닌 정답이 없는 데이터를 사용 ex) 클러스터링(군집분석)
결과를 한눈에 알기가 힘듬 -> 정답이 없기 때문에, 그 모델을 가지고 군집을 활용해 보는 수밬에 없음.
따라서 연구원에는 인기가 없음 하지만 회사에서는 인기가 많음.
1) 클러스터링(군집분석)
2) 차원 축소 : 비슷한 속성끼리 합쳐주는것
강화 학습 : ex) 알파고, 자율주행 자동차, 로봇공학
딥러닝 : 머신러닝은 통계기법을 사용해서 중요한 특성을 가중치를 많이 주고 안중요한 특성은 가중치를 주어서 사용
하지만 컴퓨터 비전러닝은 그런 방식으로 학습이 어려움
학습할때 더 많은 가중치가 있는것을 선택해서 더 많이 사용함
활성화함수는 다 정해져잇다. (어떤 학습하느냐에 따라 사용해야 되는 모델이 정해 진다면)
*역역파
수정과정의 학습 역전파
신경망 모델 만들어보기 실습
주제는
타이타닉 생존자 예측 : 디카프리오는 정말 살 수 없었을까?
데이터는 구하고자 하는 값을 1로 놓고 나머지 값을 0으로 놓는 이진분류 데이터
이진분류는 참과 거짓을 50대 50으로 데이터를 놓고 사용하는 것이 가장 좋다. (1, 0)
이진분류를 할때 활성화 함수는 relu, 마지막 출력 활성화 함수는 sigmoid
역전파 알고리즘 accuacy 를 사용한다.
1.데이터 준비하기
필요한 패키지를 인스톨해주고 필요한 라이브러리 import 해준다.
데이터 불러오기
사용할 데이터를 다운받아야하는데 타이타닉 문제는 유명한 예제라
명령어를 통해 sns웹에서 바로 데이터를 받아올 수 있다.
이제 이 데이터를 학습시킬 수 있도록 적절하게 가공해준다.
15개의 항목중 생존률과 관련성이 높은 데이터를 우선 확인해준다.

성별로 확인해보았을때 남성이 여성보다 많이 죽은것을 확인할 수 있다. 따라서 이러한 속성은 생존률 예측하는것에 도움이 되므로 학습시킬때 꼭넣어준다. 마찬가지로 다른 항목들도 비교해준다.

이건 예전에 데이터 모델링때 배운 건데 이런식으로도 연관성있는 항목을 선택할 수 있을 것 같다.
사용하고자 하는 속성을 정했다면 결측치가 있는지 확인해준뒤 그 항목들을 삭제해주거나 채워준다.
가장 많은 결측치가 있었던 age컬럼은 버리기 아깝지만 결측치가 있는 항목들을 삭제해주었다.
결측치가 2건있었던 embarked (승선 객실) 은 버릴 수도 있었지만 가장 많이 나온값 = 평균값으로 채워주었다.
교수님께서는 연구자료에서 이런식으로 데이터를 수정할 경우 문제가 발생할 수도 있다고 하셨다. 조심하자!
그뒤 학습에 필요한 컬럼을 선택해주고 컴퓨터는 범주형 자료를 인식할 수 없기 때문에 인코딩 라벨링을 진행해준다.
여성 남성을 라벨링 할때 0 과 1로 해버리면 1이 가중치를 많이 받아서 골고루 학습을 시킬수 없게 됨
남성과 여성을 비교하기만 하면됨, 객실등급도 마찬가지
따라서
식으로 원핫 인코딩을 진행해주었다.
진행해준뒤 기존 항목 삭제해주기
드디어 학습 데이터 셋을 만들어 주었다. 학습을 잘 시키는 것도 중요하지만 질 좋은 데이터를 만드는 것도 중요한것같다.
2.모델 구성하기
위에서도 설명했듯 이진 분류 지도학습의 국룰은 relu와 sigmoid 활성함수를 사용하는것
3.모델 설정하기
이부분 잘 기억해두자
4.모델 학습하기
100번 학습을 돌려주었다. 너무 많이 학습을 시킬경우 오히려 정답률이 떨어지는 경우가 많다고 한다. 실제로 옆자리 동기가 1000번 학습을 시켰더니 정답률이 매우 낮아졌다.

디카프리오가 죽은것은 아쉽지만 죽을 운명이었나보다.
2일차까지는 교수님이 설명을 잘해주셔서 크게 막히는 부분없이 진행되었다. 확실히 학교에서 나이많으신 교수님한테 코딩수업 듣다가 여기와서 들으니까 고등학교때 학교수업과 인강강사의 차이를 느꼈던 생각이 난다. (학교 교수님들도 물론 잘가르치신다 ㅎㅎ
어제 했던 크롬에서 크롤링하는것을 오늘도 하여서 전번 블로그에 남겨놨다.옆자리 동기가 버전 문제 때문에 꽤 고생을 하였다. 답답할 수 있었을 상황에서 잘 버텨주고 교수님도 끝까지 해결해주시는 모습을 보고 이것이 바로 개발자의 자질인가 싶었다. 나도 무엇이든 끈기있게 포기하지 않는 멘탈을 가지자!
'ABC 부트캠프' 카테고리의 다른 글
| ABC 부트캠프 day8 : 프로젝트 중간발표 (2) | 2024.01.24 |
|---|---|
| ABC 부트캠프 day5 : 초거대언어모델 & 생성형 AI 핸즈온 (0) | 2024.01.19 |
| ABC 부트캠프 day4 : 딥러닝 활용 (0) | 2024.01.18 |
| ABC 부트캠프 day3 : 딥러닝 기초 및 실습 (0) | 2024.01.17 |
| ABC 부트캠프 day1 : 데이터 수집을 위한 크롤링 (0) | 2024.01.15 |


