오늘 실습할 주제:
– 다중 분류: MNIST 0-9까지 숫자 이미지 예측하기
– 회귀 문제: 자동차 연비 예측하기
– 이미지 인식: 강아지 고양이 이미지 예측하기
MNIST는 딥러닝계의 "Hello World"

train 은 6만건, test는 1만건(성능평가)
트레인 데이터에서 만건정도 떼어서 검증데이터(val) 로 사용하고 싶다 (쪽지 시험)
중간중간에 한번씩 학습하지 않은 데이터를 주면서 잘 학습되고 있는지 확인한다.
보통 7:3으로 비율을 나눔
하지만 훈련데이터가 부족할 경우 사용하지 않아도 된다(필수는 아님)
이유는 검증데이터는 학습시키는 데이터가 아니기때문에 데이터셋이 충분히 확보 되있을때만 사용한다.
코드를 사용하여 분리
2차원데이터를 1차원 데이터로 바꿔줘야하는데 (dense 층을 사용하기 위해서)
28 * 28 = 784 이므로 [0][0] = [0], [0][1] = [1] 이런식으로 바꿔준다.
또한 신경망은 스케일에 매우 민감!
데이터 값이 0부터 256까지 되어있는데 (픽셀별 밝기) 가중치는 곱연산이기 때문에 값이 너무 커져버리면 계산할때 튀어버릴수있음
따라서 이값을 스케일링하는 과정을 거쳐줘야한다.
크게 세가지 방법이 있는데
1. 정규화(MinMax) : 범위가 정해져있는 값
2. robust normalization
3. standardzation : 범위가 정해져 있지 않으면 이것을 사용하면 된다.


y_train 값은
array([2, 7, 6, ..., 3, 4, 5], dtype=uint8)이러한 0부터 9까지의 값 형태를 가지고 있지만 컴퓨터는 이러한 구간 형태를 이해할 수 없기 때문에 범주형 형태로 바꾸어 줘야한다. 어제 했던 원핫 인코딩을 하면 된다.
9 -> 00...001
8 -> 00...010 이런식으로 각 구간에 1이 있는것을 찾아준다고 생각하면 된다.
이진분류 활성화 함수는 어제 sigmoid함수를 사용했지만 다중 분류 활성화 함수는 softmax 함수를 사용한다.
sigmoid는 그대로 함수를 출력하지만
softmax는 확률을 계산해서 비율로 출력한다. 가장 유력한 함수의 값을 키워줘서 학습을 잘 시킨다.
배치사이즈란 중간에 쉬고 가중치 보정하는 작업. 학습효과가 늘어난다.
배치사이즈가 크면 클수록 자잘하게 나워서 학습하기 때문에 시간이 증가하지만 학습은 더 잘됨

과대적합 = 너무 많은 학습을 시키다보니 훈련데이터랑 검증 데이터가 차이가 많이남 , 이상한 방향으로 파고든다.
그렇게 되면 융통성이 없는 친구가 되어버림 자기가 공부한것만 너무 달달 외우다 보니 공부한것만 맞추고 새로운것은 잘 못맞추게 됨
따라서 train_acc와 val_acc가 만나는 지점이 가장 최적으로 학습 train_acc가 높아봤자 성능은 val_acc 이므로 위에꺼에 집착하면 안된다.
더 성능을 높이려면 데이터셋을 더 확보하는것이다. 학습을 많이 시키는것이 아니라.
해결방법으로는 배치를 키우던가 검증데이터를 좀 줄이고 drop을 해줘서 끊어준다.
정확도는 성능지표로 사용할수 없다 이유는 정상 99명 암환자 1명의 테스트셋이 있을때 정상 100명이라는 결과가 나왔을 경우 정확도는 99%지만 이것은 목적과 맞지 않는다.
항상 데이터 셋은 불균형한 경우가 많기 때문에 보통 f1스코어를 많이 사용한다.
또한 결과를 heatmap 형태로 나타낼수도 있다.

확실히 3과 5를 가장 많이 헷갈리는 모습 인간과 비슷하다.

분류보고서를 표현하는 것은 report 명령어로 표시한다.
다음주제는 유명한 회귀문제로
자동차 연비(MPG) 예측하기
- 1970년대 후반 1980년대 초반의 자동차 연비 예측

csv 파일을 열기 위해 note pad++ 를 다운받아 준다음에 열어서 데이터를 확인해준다. UTF-8형식이라 따로 인코딩 하지 않아도 되는것 확인!
코랩에 파일을 넣어준뒤 데이터를 받아와준다.
헤더가 없는 데이터였기 때문에
헤더를 none으로 숫자로 채워주고
를 통해 컬럼 정보를 수동으로 입력해준다.
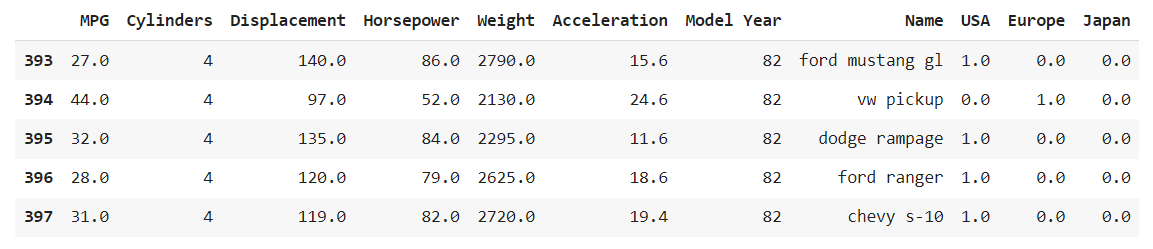
결측치가 있는지 데이터 row수가 맞는지 확인부터 해준다. 397개의 데이터랑 헤더를 포함해 398이 나와야 한다.
차 생산지명이 수치형이기 때문에 범주형으로 바꿔 줘야한다.
텍스트로 되어있는 범주형 데이터(어제했던 타이타닉 성별)는 get.dumies를 써주면되지만 (자동으로 바꿔줌) 숫자로 되어있는 범주형 데이터는 하나하나 따로 원핫인코딩 해줘야된다.
origin으로 따로 빼준다음 (어차피 있던 데이터는 삭제해야되기때문에)
생산지별로 각각 간단한 조건문을 사용하여 일치할때 각각의 컬럼에 1을 넣어준다.
다음으로 이미지 분석 문제
문제정의: 강아지(1), 고양이(0) 예측하는 이진분류 문제
데이터가 크기 때문에 Google api를 통해 데이터를 불러온다. 드라이브로 다운받으면 시간이 너무 오래걸림.
tmp안에 zip 파일로 저장되는데 이것을 개별로 압축풀기하는것 보다는 코드로 압축을 풀어줘야 편하고 빠르다.
압축 풀고 각각의 데이터를 폴더를 나눠준다.

사진은 2차원이지만 기존에 학습했던 Dense층은 1차원이기 때문에 사진 정보가 잘 학습이 되지 않아서
컴볼루션 층이라는 새로운 개념 2차원으로 입력 할 수 있도록 만든다.
1차원으로 학습시키면 공간정보가 손실됨 (강아지의 털이 수염인지 머리카락인지 코위에 있나 없나 알수없음)
하지만 2차원으로 학습시면 공간정보를 확보할 수 있음.
필터를 씌우면 학습할 때 중요한 정보를 강조시키고 나머지 배경을 없애 버림
근본적으로 데이터가 많아야 되긴함.
하지만 물리적으로 한계가 있기 때문에 이미지를 증식시키는 이미지 제네레이터를 활용한다.
(더 밝게, 더 어둡게, 회전되거나 자르거나 반전시켜서)
여기서 주의할점은 train데이터만 이미지 증식을 해주고, test데이터는 이미지 증식을 해주지 않는다
어려운 문제는 풀어도 좋지만 굳이 맞출필요는 없다.

이제 데이터는 다 준비되었다.
CNN 모델을 구성해준다.

구성을 나타낼수 있는 코드
코랩 프로모델이라 a100 gpu를 사용했음에도 10분정도 걸린거같다.
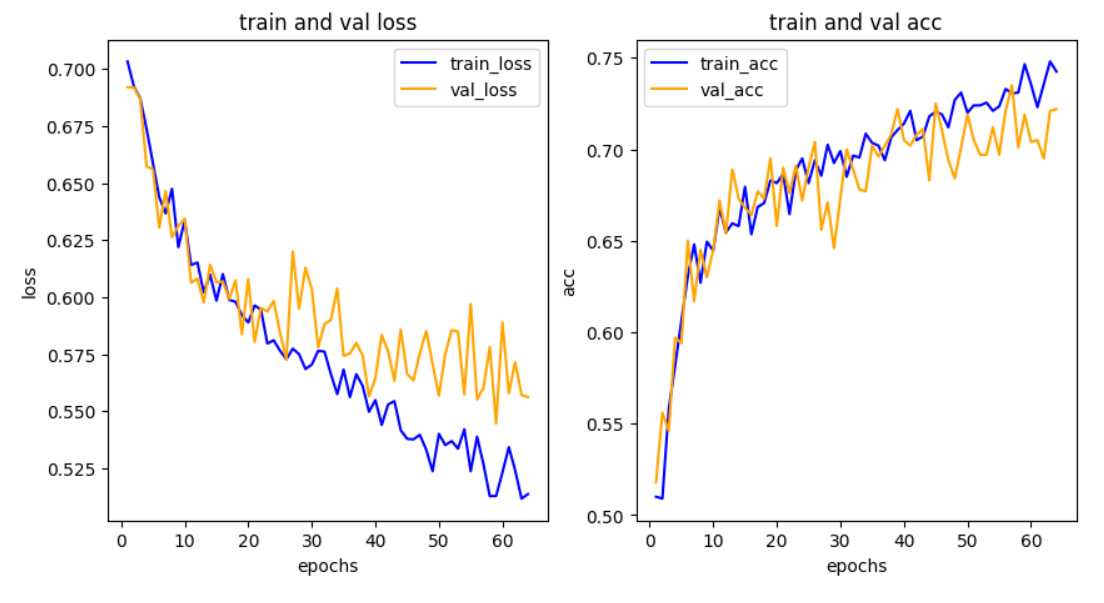
train_acc와 val_acc가 계속해서 우상향하는 그래프기 때문에 epochs값을 더 늘려도 괜찮다.
그 이후로는 사전학습 된 모델을 사용해서 다시 학습을 시켜본다.


정확도가 점점더 떨어지는 모습...
이미 학습된 모델이기 때문에 학습을 많이 한다해서 정확도가 크게 상승하진 않는다. 중간에 한번씩 위로 튀는 구간이 있는데 그 이유를 좀 찾아 봐야 될것같다.
'ABC 부트캠프' 카테고리의 다른 글
| ABC 부트캠프 day8 : 프로젝트 중간발표 (2) | 2024.01.24 |
|---|---|
| ABC 부트캠프 day5 : 초거대언어모델 & 생성형 AI 핸즈온 (0) | 2024.01.19 |
| ABC 부트캠프 day4 : 딥러닝 활용 (0) | 2024.01.18 |
| ABC 부트캠프 day2 : 머신러닝 딥러닝 기초 (0) | 2024.01.16 |
| ABC 부트캠프 day1 : 데이터 수집을 위한 크롤링 (0) | 2024.01.15 |


